
Deep Learning in 2021
This post is going to cover the state of deep learning in 2021 with particular emphasis on AI infrastructure and deep learning tooling. If you're coming from a theory-based university classroom, get ready for an exhausting amount of detail. The classic pattern of "just feed some data through the network and backpropogate" is still the truth, but it takes ~10x more effort beyond the network to get anything useful.
Theory
TODO
Requirements
Language: Python
The lingua franca of modern DL is Python. All the major research codebases are in Python, the major DL frameworks all have Python bindings, and the vast majority of tooling is written for Python users. I don't know of any big league research organizations that use anything other than Python.
CPU Training on Machine
This is the "Hello World" of DL, but we'll explore this scenario in some detail so we can reference it in later sections. Let's use the torchvision library from the PyTorch team to train a simple classifier on MNIST.
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(
(0.1307,), (0.3081,))
])
# NOTE: Dataset downloaded to local machine
trainset = MNIST(root='./data', train=True, download=True, transform=transform)
trainloader = DataLoader(trainset, batch_size=4, shuffle=True, num_workers=2)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x)
net = Net()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for epoch in range(2):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# NOTE: Data loaded from disk into RAM
inputs, labels = data
optimizer.zero_grad()
# NOTE: CPU computes forward pass, backward pass, update weights
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 2000 == 1999:
print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
Several things verify that our model works correctly:
- There were no interpreter errors when we run the code (i.e. no crashes)
- The loss decreases
- The accuracy on the validation increases
This example is representative of how tutorials and most universities teach deep learning, but it is not useful in practice. Let's dig in on several of the assumptions that make this example so elegant. First, the MNIST dataset is tiny, only 9.9 MB, and static. Why do we focus on this? Because in practice, the datasets we want to use to power insights or new features are massive and dynamic (constantly changing). It is easy in this example to download MNIST to our local device to train the model - it only takes a few seconds to make an HTTP request to the server with the tarball of the MNIST dataset and download the whole dataset. And once the dataset is in memory, the time cost of loading small batches of the dataset into our model on the CPU is effectively optimal. MNIST is just 28x28 pixel images - it takes almost no time to load a small batch of 28x28 images, and those images take up almost no RAM. You can't beat the speed of just loading data from disk onto CPUs without fancy I/O optimizations which we'll cover in a later section. If we were lazy and inefficient, we could always re-download the MNIST dataset from the server every time we trained the model and it would still work. We would only add a few seconds to each training run, and the amount of memory we consume is only 9.9 MB.
Also observe that all of the operations in the function above.. TODO
Distributed Deep Learning
Now we that we've shown the example above, we can throw away almost every assumption we just made. In real life, DL / AI / ML is not magic. All we are doing is using backpropagation to compute gradient updates for an optimization function. The magic is cleverly selecting a model that maps our input data to our objective, sometimes being clever with how we train the model(s), and training on as much data we have available. For all of the literature on "efficient training" and network architectures that have stronger capacity to generalize, in practice we want to train the model using as much data as humanly possible. Practically any clever DL trick we can think of can be ignored if we have more training data. So if you're a DL practitioner in an organization, and the goal is to get a model you can actually use (in business or research), your main goal is to acquire as much data as possible. If you're successful and can acquire a massive dataset (>10TB), you will be able to train something useful, but your dataset does not fit in memory. Furthermore, your dataset is probably generated via an internal ETL pipeline, or by interns tasked with getting you more data, which means it changes over time.
It will be useful to understand the role of distributed communications in DL before digging into distributed deep training. To speed up model training on a large dataset using multiple GPUs, we turn to "data parallel training". The plain english explanation is we can speed up model training by sending different chunks (i.e. "batches") of the very large dataset to each GPU, have each GPU compute weight updates separately, and then add up those weight updates (i.e. "gradients") to produce one global weight update at each time step. The step where we add up the weight updates is known as all_reduce(), and we'll cover it in more detail in the MPI section. The copy of the model on each GPU will have the same weights after each iteration of backpropagation, but we've now consumed # gpu's times the data in a single iteration. Throughout this process the GPU's need to be in constant communication, and so a distributed communications protocol is required.

Hardware
The bottom layer of our distributed training stack is hardware. Our network has CPUs, GPUs, and in the future perhaps TPUs and FPGAs. For modern deep learning, the only GPUs anyone uses are sold by NVIDIA - they hold a monopoly on the market. Why? How? The short story: NVIDIA owns CUDA. CUDA makes it easy to write code that can take advantage of GPU parallelization. Deep learning, and especially computer vision based deep learning, is a lot of convolutions. Convolutions are "shift, add, sum" - very easy math to parallelize, extremely fast operation when parallelized. All the major numerical computation libraries built in CUDA support to use GPUs since it was first and easiest. Only NVIDIA GPUs support CUDA, so by default you can now only use NVIDIA GPUs for deep learning.
CUDA is a parallel computing platform and programming model that makes using a GPU for general purpose computing simple and elegant. The developer still programs in the familiar C, C++, Fortran, or an ever expanding list of supported languages, and incorporates extensions of these languages in the form of a few basic keywords.... These keywords let the developer express massive amounts of parallelism and direct the compiler to the portion of the application that maps to the GPU.
In 2016 Google announced the Tensor Processing Unit (TPU), an application specific integrated circuit (ASIC) specifically built for deep learning. Without going into hardware detail, TPUs are significantly faster than GPUs for deep learning. GPUs are multipurpose - they are graphics processing units, literally designed to handle graphics workloads. It just so happens that GPUs are effective for deep learning, but they are not power or memory efficient. Unlike GPUs, TPUs leverage systolic arrays to handle large multiplications and additions with memory efficiency 1. Google initially used its TPUs internally to handle its massive DL workloads, but now offers TPU enabled training and inference as a cloud offering and for sale.
Network Switching
Message Passing Interface (MPI)
Message Passing Interface (MPI) surfaced out of a supercomputing computing community working group in the 1990's. From the MPI 4.0 specification2:
MPI (Message-Passing Interface) is a message-passing library interface specification... MPI addresses primarily the message-passing parallel programming model, in which data is moved from the address space of one process to that of another process through cooperative operations on each process. Extensions to the “classical” message-passing model are provided in collective operations, remote-memory access operations, dynamic process creation, and parallel I/O
MPI specifies primitives (i.e. building blocks) that can be used to compose complex distributed communications patterns. MPI specifies two main types of primitives:
- point-to-point : one process communicates with another process (1:1)
- collective : group of processes communicates within the group (many:many)
These primitives are obviously useful for distributed deep learning. Each GPU process has weight gradients we need add up? Use the all_reduce() primitive. Each GPU process P_i comes up with a tensor x_i that needs to be shared to all other GPU processes? Use the all_gather() primitive, etc. Below is a helpful graphic directly from the MPI 4.0 standard to cement the concept.

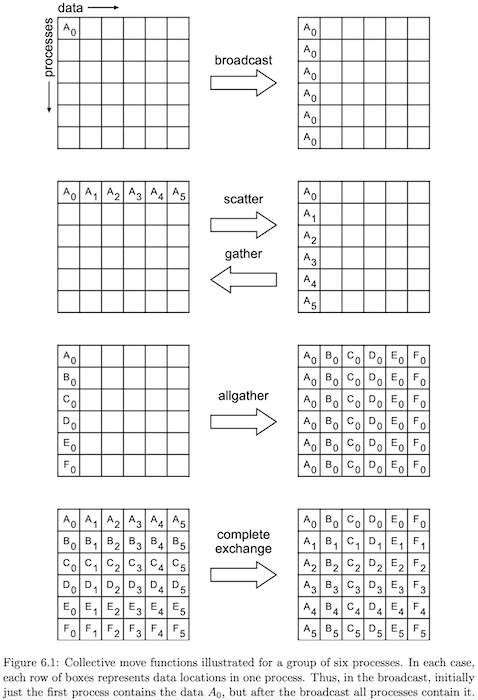
Distributed Training Frameworks
Horovod: https://youtu.be/SphfeTl70MI
Comparison of NVLink vs alternatives: https://arxiv.org/pdf/1903.04611.pdf
Single GPU Training
This is the same scenario as "CPU Training on Machine", but we now have 1 GPU in addition to our CPUs.

https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader
Multi GPU, Single Node Training
This is the same scenario as "Single GPU Training", but we now have >1 GPUs on our node. Most deep learning practitioners in academia, small industry research groups, and hobbyists operate under this scenario. Simply put, you take as many GPU's as you can afford and put them on a single physical machine. This avoids the need to consider inter-machine networking, and in reality, this still works for most SOTA research.
As seen in the figure below, the deep learning framework creates a process to manage each GPU's training. The GPU's each receive a different mini-batch of the data for the forward pass, compute gradients, and then proceed to all_reduce. Now we have two main ways to perform the all_reduce.
The first way is to designate one of the processes the master process, usually the process managing GPU 0, and have each GPU process send gradients to the master process. The master process accumulates all gradients and sends the reduced gradients back to each GPU process. Now each GPU has the same gradients to update weights. This is particularly effective for this scenario because the GPUs are all on the same machine; they are connected by a dedicated IO bus that supports extremely fast inter-GPU communication. In PyTorch this the DataParallel[^3] model
TODO: Does the second way exist??? What are the tradeoffs if so.

https://pytorch.org/tutorials/intermediate/dist_tuto.html https://pytorch.org/docs/stable/distributed.html
Multi GPU, Multi Node Training
All processes in the process group3 use ring communication

Multi GPU, Multi-Node Training Cloud
Truly large-scale models are trained in the multi-gpu, multi-node setting. Examples include GPT-3, DeepMind's DOTA model, and Google's DL driven recommendation algorithms. Recall that a 'node' is typically a physical machine with 8 GPU's. When practitioners say a model was trained on 1024 GPU's, that precisely means the model was trained on 1024 / 8 = 128 physical nodes, each with 8 GPU's.
Let's take a moment to think of the broad challenges here before getting into specifics. We're now training a model across 128 separate physical machines. This introduces problems related to communication, i.e. that the physical nodes will have to communicate with each other over some network, and problems of speed. It takes time to load each batch of data from the data store to each physical machine. What if the data size is large (videos, raw audio), and what if DB reads are slow?
6a. Distributed Training Frameworks (Training Backends) a. MPI b. DDP (NCCL) c. Horovod https://github.com/horovod/horovod d. BytePS e. Parameter Servers
https://pytorch.org/tutorials/intermediate/rpc_param_server_tutorial.html
Cloud Workflows for Deep Learning
Deep Learning Frameworks
Higher Level Frameworks
Keras, Ignite, Lightning
Data Ingestion Patterns
Frameworks*
Let's talk about frameworks for a second. This section has an asterisk because I want to make it clear these are opinions, not facts. Frameworks provide higher level patterns / abstractions that structure your usage of a tool and in theory enable you to do more complex tasks with less effort. I say in theory because at worst, the frameworks themselves have a steep learning curve and don't enable you to do anything the underlying tool couldn't do.
PyTorch Ignite with PyTorch
- Elegant
engineconstruct to manage logging, hooks, training execution - Clean interface over PyTorch distributed module
- Narrow set of excellent utilities for logging, checkpoint management, etc.
- Poor support for custom code - rewriting open source code to operate with an ignite engine is difficult
- Low-level, sits one level above PyTorch so not too abstract
- Small but active developer community
PyTorch Lightning with PyTorch
- Strong abstractions for new developers
- Excellent support for multi GPU training
- Integrations with upcoming deep learning backends
- Large developer community
- The guy who started PyTorch Lightning is shameless, he goes for personal attention at every opportunity, and they misrepresent other's work as the Lighning's work. -10.
Keras with TensorFlow
- Excellent abstractions over TensorFlow for new developers
- Such widespread usage that Google moved to provide first-class support
- TensorFlow adopted many core ideas
- No longer needed to advanced TensorFlow
- Doesn't play nice with the entire Google Cloud DL ecosystem
Reading List (Links)
- Andrej Karpathy's Recipe for Training Neural Networks (2019)
- https://lambdalabs.com/blog/introduction-multi-gpu-multi-node-distributed-training-nccl-2-0/
Footnotes
-
https://cloud.google.com/blog/products/ai-machine-learning/what-makes-tpus-fine-tuned-for-deep-learning ↩
-
https://NEED_THE_LINK_FOR_DATA_PARALLEL.com ↩